Accurate, real-time lip-syncing for Unity
We are excited to present our real-time lip-syncing Unity asset SpeechBlend with viseme blendshape support.
Visemes are the facial expressions made when the mouth is producing certain sounds. Think of the circular shape your mouth makes when creating an “OOO” sound. SpeechBlend uses machine learning to accurately predict mouth shapes from a continuous audio source output in Unity. See a demo of live lip-sycing using SpeechBlend:
Setting up SpeechBlend is as simple as:
- Dropping the SpeachBlend script onto a character
- Pointing it to the character’s head audio source
- Specifying the head mesh along with the viseme blendshapes.
SpeechBlend can be used with a single jaw joint or “mouth open” blendshape for simple mouth tracking, but to take full advantage of the lip-syncing features it’s best to use a character model with viseme blendshapes available. This can be a character model from Daz Studio, iClone, or any custom character with a similar set of blendshapes. Here is a table showing the viseme blendshape sets currently supported:

SpeechBlend provides a variety of options for tuning lip-syncing accuracy and performance.
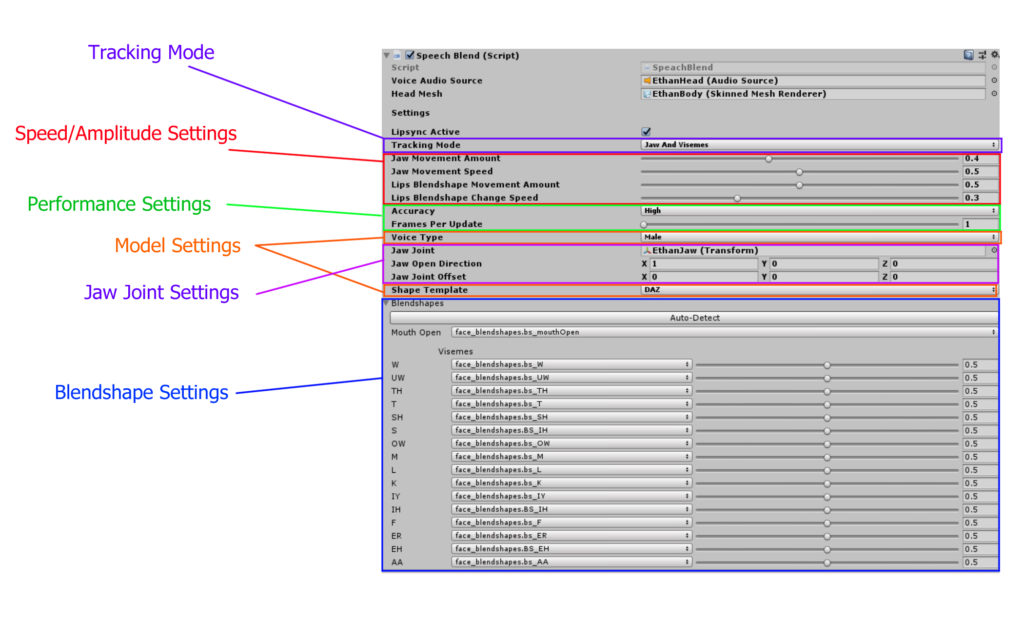
- Toggle between jaw-only and jaw+viseme tracking
- Mouth movement speed and amplitude
- Model complexity (Low, Medium, High) and update rate
- Individual viseme amplitude tuning
For more information, check out the SpeechBlend Documentation and Setup Guide.